Group Publications highlights
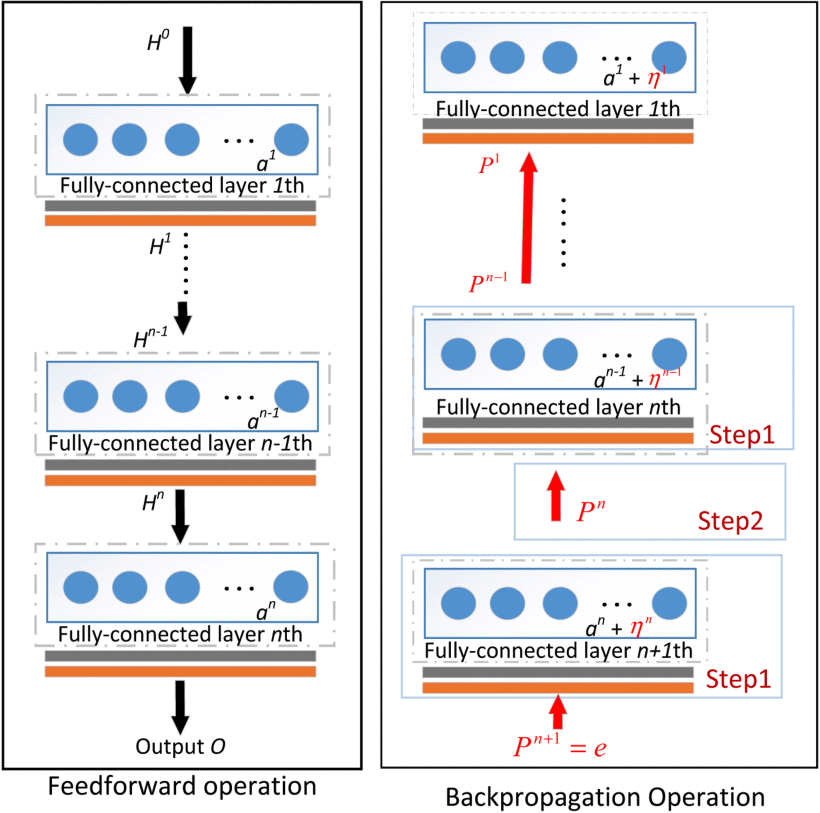
{“Gradient descent optimization of learning has become a paradigm for training deep convolutional neural networks (DCNN). However, utilizing other learning strategies in the training process of the DCNN has rarely been explored by the deep learning (DL) community. This serves as the motivation to introduce a non-iterative learning strategy to retrain neurons at the top dense or fully connected (FC) layers of DCNN, resulting in, higher performance. The proposed method exploits the Moore-Penrose Inverse to pull back the current residual error to each FC layer, generating well-generalized features. Further, the weights of each FC layers are recomputed according to the Moore-Penrose Inverse. We evaluate the proposed approach on six most widely accepted object recognition benchmark datasets”=>”Scene-15, CIFAR-10, CIFAR-100, SUN-397, Places365, and ImageNet. The experimental results show that the proposed method obtains improvements over 30 state-of-the-art methods. Interestingly, it also indicates that any DCNN with the proposed method can provide better performance than the same network with its original Backpropagation (BP)-based training.”}
Y. Yang, Q. M. Jonathan Wu, X. Feng and T. Akilan
IEEE Transactions on Pattern Analysis and Machine Intelligence (Volume 42, Issue 11, May 2019)
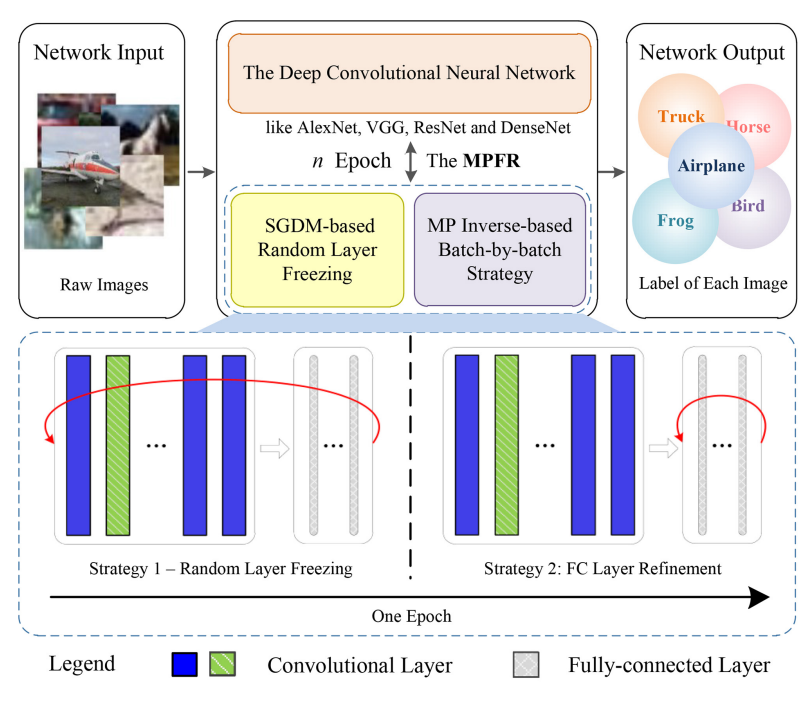
Recent work has utilized Moore-Penrose (MP) inverse in deep convolutional neural network (DCNN) learning, which achieves better generalization performance over the DCNN with a stochastic gradient descent (SGD) pipeline. However, Yang’s work has not gained much popularity in practice due to its high sensitivity of hyper-parameters and stringent demands of computational resources. To enhance its applicability, this paper proposes a novel MP inverse-based fast retraining strategy. In each training epoch, a random learning strategy that controls the number of convolutional layers trained in the backward pass is first utilized. Then, an MP inverse-based batch-by-batch learning strategy, which enables the network to be implemented without access to industrial-scale computational resources, is developed to refine the dense layer parameters. Experimental results empirically demonstrate that fast retraining is a unified strategy that can be used for all DCNNs. Compared to other learning strategies, the proposed learning pipeline has robustness against the hyper-parameters, and the requirement of computational resources is significantly reduced.
W. Zhang, Y. Yang, T. Akilan, Q. M. Jonathan Wu and T. Liu
IEEE Transactions on Cybernetics (Volume 55, Issue 1, January 2025)
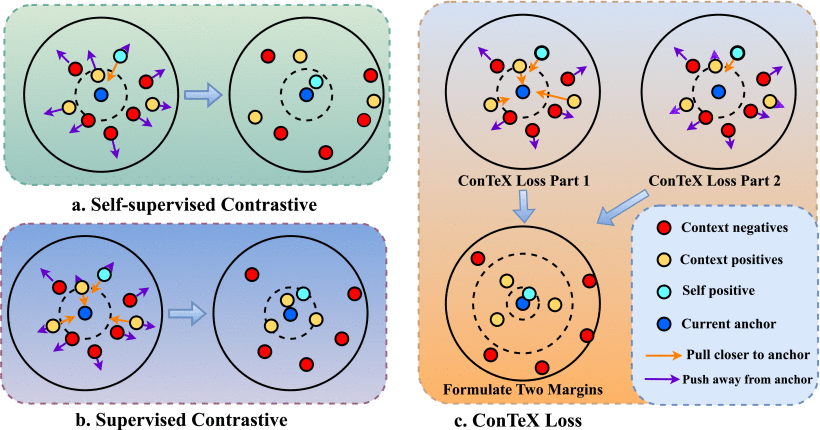
Contrastive learning has gained popularity and pushes state-of-the-art performance across numerous large-scale benchmarks. In contrastive learning, the contrastive loss function plays a pivotal role in discerning similarities between samples through techniques such as rotation or cropping. However, this learning mechanism can also introduce information distortion from the augmented samples. This is because the trained model may develop a significant overreliance on information from samples with identical labels, while concurrently neglecting positive pairs that originate from the same initial image, especially in expansive datasets. This paper proposes a context-enriched contrastive loss function that concurrently improves learning effectiveness and addresses the information distortion by encompassing two convergence targets. The first component, which is notably sensitive to label contrast, differentiates between features of identical and distinct classes which boosts the contrastive training efficiency. Meanwhile, the second component draws closer the augmented samples from the same source image and distances all other samples, similar to self-supervised learning. We evaluate the proposed approach on image classification tasks, which are among the most widely accepted 8 recognition large-scale benchmark datasets: CIFAR10, CIFAR100, Caltech-101, Caltech-256, ImageNet, BiasedMNIST, UTKFace, and CelebA datasets. The experimental results demonstrate that the proposed method achieves improvements over 16 state-of-the-art contrastive learning methods in terms of both generalization performance and learning convergence speed. Interestingly, our technique stands out in addressing systematic distortion tasks. It demonstrates a 22.9% improvement compared to original contrastive loss functions in the downstream BiasedMNIST dataset, highlighting its promise for more efficient and equitable downstream training.
H. Deng and Y. Yang
IEEE Transactions on Multimedia (Volume 27, December 2024)
In this paper, we believe that the mixed selectivity of neuron in the top layer encodes distributed information produced from other neurons to offer a significant computational advantage over recognition accuracy. Thus, this paper proposes a hierarchical network framework that the learning behaviors of features combined from hundreds of midlayers. First, a subnetwork neuron, which itself could be constructed by other nodes, is functional as a subspace features extractor. The top layer of a hierarchical network needs subspace features produced by the subnetwork neurons to get rid of factors that are not relevant, but at the same time, to recast the subspace features into a mapping space so that the hierarchical network can be processed to generate more reliable cognition. Second, this paper shows that with noniterative learning strategy, the proposed method has a wider and shallower structure, providing a significant role in generalization performance improvements. Hence, compared with other state-of-the-art methods, multiple channel features with the proposed method could provide a comparable or even better performance, which dramatically boosts the learning speed. Our experimental results show that our platform can provide a much better generalization performance than 55 other state-of-the-art methods.
Y. Yang and Q. M. Jonathan Wu
IEEE Transactions on Neural Networks and Learning Systems (Volume 30, Issue 11, November 2019)
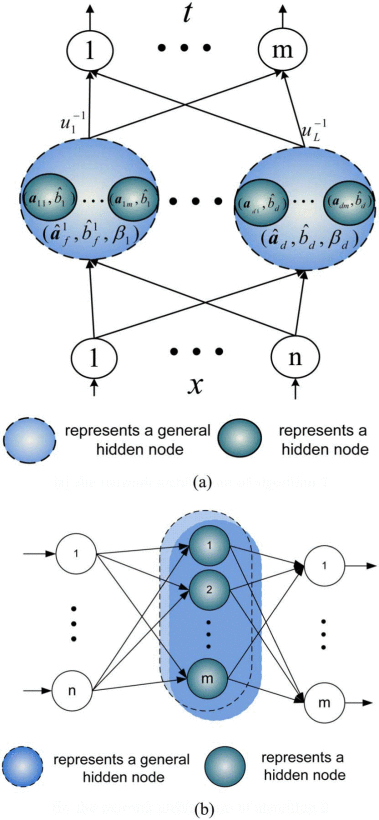
As demonstrated earlier, the learning effectiveness and learning speed of single-hidden-layer feedforward neural networks are in general far slower than required, which has been a major bottleneck for many applications. Huang et al. proposed extreme learning machine (ELM) which improves the training speed by hundreds of times as compared to its predecessor learning techniques. This paper offers an ELM-based learning method that can grow subnetwork hidden nodes by pulling back residual network error to the hidden layer. Furthermore, the proposed method provides a similar or better generalization performance with remarkably fewer hidden nodes as compared to other ELM methods employing huge number of hidden nodes. Thus, the learning speed of the proposed technique is hundred times faster compared to other ELMs as well as to back propagation and support vector machines. The experimental validations for all methods are carried out on 32 data sets.
Y. Yang and Q. M. Jonathan Wu
IEEE Transactions on Cybernetics (Volume 46, Issue 12, December 2016)
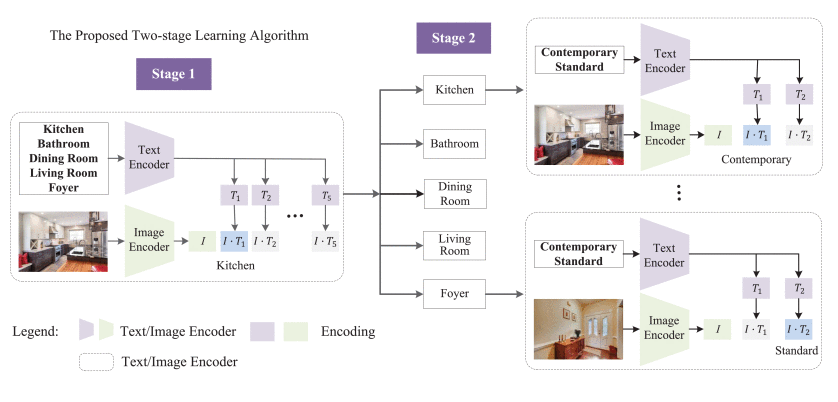
The significance of the real estate search engine in the economy necessitates the development of a reliable room image luxury level annotation method that addresses current limitations, including the inability to assess room quality, underutilization of deep network capacities, and the need for more annotated house images. This paper proposes a novel real estate image annotation model, leveraging the diffusion model and contrastive language-image pre-training (CLIP) network, through a multi-stage algorithm. First, the diffusion network is employed as a data augmentation technique to generate additional real estate images for network training. Then, a CLIP model is utilized to categorize images into the kitchen, bathroom, dining room, living room, and foyer. Finally, five CLIP models assess the condition of each room, categorizing it as contemporary and standard. Experimental results on a newly collected real estate image dataset demonstrate that the proposed approach surpasses existing house image classification algorithms.
H. Deng, W. Zhang, Y. Yang and E. Nejad
2024 IEEE International Conference on Consumer Electronics (ICCE)
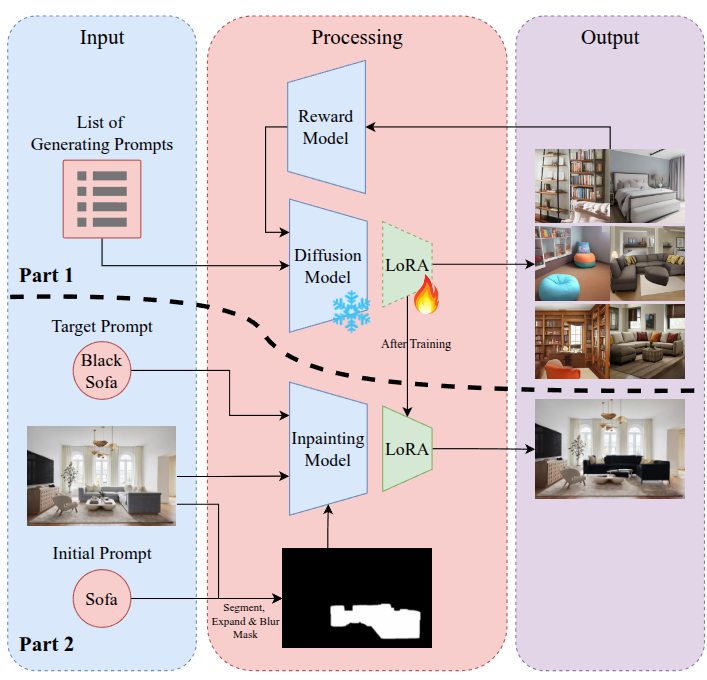
Virtual staging has revolutionized the real estate industry by automating the redesign of interior images based on user instructions. This paper introduces an innovative Agentic AI Workflow for end-to-end, prompt-based contextual virtual staging, leveraging multiple specialized AI components. Our framework integrates advanced segmentation models and reinforcement learning-enhanced inpainting models to accurately interpret and execute user instructions, resulting in highly realistic and aesthetically pleasing property visuals. A key innovation is the use of Low-Rank Adaptation (LoRA) to fine-tune the Stable Diffusion model specifically for inpainting tasks. By employing a reinforcement learning technique tailored for diffusion models, we optimize LoRA parameters to maximize aesthetic quality and adherence to user prompts. This agentic approach enables each AI component to independently refine its specialized function while seamlessly collaborating within the workflow, enhancing overall flexibility and user satisfaction. To rigorously evaluate our methodology, we developed a standardized benchmark workflow to assess our proposed method across various categories, including furniture, functional elements, and decor. Experimental results demonstrate that our Agentic AI Workflow significantly outperforms traditional methods, achieving higher aesthetic scores and greater user preference, particularly in furniture and decor, while exhibiting reduced performance variability for consistent and reliable outcomes. Beyond real estate, the versatility of our Agentic AI Workflow extends its applicability to diverse domains such as architecture, e-commerce, and digital content creation. This research highlights the potential of agent-based AI systems to deliver customizable and high-quality visual transformations, paving the way for innovative applications across multiple industries.
S. Murray, H. Deng, Y. Yang and E. Nejad
2025 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE)